Oberlin Blogs
Winter Term Recap
February 5, 2011
Tess Yanisch ’13
It's early February and Winter Term is officially over. The past week was technically free time--a comfortable lull in which to completely relax, or, in the case of those people whose Winter Term projects were performances of some kind, a final week in which to cram increasingly intense rehearsals. I'm looking forward to going to those shows. Last night was the Winter Term Circus, a delight to watch (two words: dueling accordions). There's also Bait, Eurydice, and Firefly: The Big Go'ram Musical, which is written, directed, and performed by fellow Sci-Fi-Hall-ians. (Please note: that's how they spell it. I spell it "gorram," and nothing and nobody in the 'verse is gonna stop me.) They are all hard at work. That show is tonight, and I'm really looking forward to it.
But I am done, finished, carefree. The two other psychology researchers I was training in proved exceptionally competent and have made lots of progress. My computational model is complete and turned in. My only obligations this week are lifeguarding and a few more shifts at the co-op. I am quite content with this schedule. It leaves me lots of time to read--comic books, social science books, werewolf books.
But reading isn't all I've been up to. I'm going to revisit some of the things I mentioned in my first Winter Term-related blog and follow them up for those who are interested in what I accomplished. I'll probably go into far too much detail about my model, and for that reason, I'm putting it last.
First comes a wonderful discovery that I made at the co-op. It was Potato Night (a special meal, akin to the broccoli one mentioned in an earlier blog). I helped myself to one or two of what appeared to be normal, albeit bite-sized, baked potatoes, with wrinkled brown skins. I ate half of one and OH MY GOD IT WAS PURPLE. Purple! Bright, bright purple. I was inordinately excited.
It turns out these are called blue potatoes. I don't know why I was so tickled to find out they existed; I suppose I am unused to natural produce being violently violet, at least on the inside. Eggplants, plums, and grapes can be purple on the outside, but in this case the flesh itself was of a vivid hue.
Another co-op related piece of news: we got a shipment of white flour, and I made cinnamon rolls again, the traditional way this time. They came out of the oven at about 9:00 PM. Since any baked goods are best warm, I texted Emma and Guy and they came in to try some, along with a passel of people Emma had rousted out of the lounge. I spent the next fifteen minutes being showered with compliments: one person informed me that he'd gladly join a religion based around the cinnamon rolls (I promised him the recipe). It was quite flattering.
I made two pans of the cinnamon rolls. About a third of them were consumed in this first wave.
When I came in at about 11:00 the next morning, all that was left on the pans were the small round sugar stains indicating where each roll had once stood.
The final meal in our co-op was a big blow-out feast, consisting of nachos and pizzas. I realized that I've become unaccustomed to meat over the past month; we've had chicken a few times, and beef maybe twice, but now we had lots of ground beef and buffalo. It was great, but it seemed a lot heavier than the mostly-vegetarian fare I've been used to. Interesting.
There was also real ginger ale. We're talking serious ginger; this would be great to have on hand if you were sick, because just smelling it clears your sinuses. I loved it.
But my actual project, too, deserves follow-up. For those of you who don't remember, I was taking a class on computational modeling, the process of designing simulations of situations. A computational model doesn't have to be implemented by a computer, but it must be governed by strict rules and processes--one could argue that Dungeons and Dragons is a computational model.
The fun part is deciding what these rules and processes should be.
We learned three different platforms for coding. The simplest was an Excel spreadsheet. You can use formulas to affect the output of one cell given input in another. This only works for systems-dynamics models, though--models of a system as a whole. You could see the average change in a population at a given time, but not what happened to Person X specifically. A good example of this is the disease model. Given an initial population size, the number of people sick initially, and the contagion rate, you can see how long it takes for everyone to become infected, or for 50% of the population to become infected. But you can't see when one particular one of them gets sick.
One of the people in my class used a more elaborate version of this as his project, adding a recovery rate and a disease mutation rate. He modeled the seasonal flu. People went from susceptible to infected to recovered, then (eventually) back to susceptible. Certain parameters did indeed produce a regular spike in the infection rate, just like our yearly flu.
The platform I used is called NetLogo. It's an agent-based model--you can affect what happens to each person in your system individually, rather than to the population as a whole. There's a neat display so you can see all this happening, which you don't have on Excel (unless you create a graph, which gives you a rough visual representation). In this, you can create agents called "turtles." Each turtle can have attributes that you can define--color, number of connections, already carried out Procedure W, etc. You, the modeler, have to create all of this. NetLogo has its own programming language that you must use to instruct it.
In other words, I, who had no previous experience in programming whatsoever, kind of taught myself how to program. I'm sure my code was not as efficient or elegant as that of someone more familiar with the syntax and tricks of NetLogo or more experienced in programming in general, but I copied and modified from the examples in the model library and got a functional program. It was frustrating at times, but immensely satisfying when I got it right.
There was another program, Nova, which a professor at Oberlin has created/is creating. (If you're interested in modeling, there's a website: nova.oberlin.edu.) It's a work in progress: the students in our class who used it gave him feedback and he's tinkered with it in response. It can work as either a systems-dynamics or an agent-based model. You create "stocks"--current values--and "flows"--inputs and outputs to and from the stocks--to model your system. It's even more difficult to describe than NetLogo, so I'll just say it's a very interesting program and has a lot of potential. You don't need to program it the way you do NetLogo, but you do have to connect and define the stocks correctly. It's pretty flexible: someone in the class used it to model language comprehension!
I realize this may be confusing. One of the class assignments was to compare and contrast the three platforms. Here are the main points from mine.
- "All three programs allow the user to input rules determining the behavior of the model. In Excel, this is explicitly formulaic--mathematical constructs define the behavior of most cells. NetLogo is more abstract: inputs can be simple numbers, or they can be variables, but I have not yet determined a method for telling NetLogo to use the value of a variable to affect the behavior of other variables. For instance, in Excel, one can set the value of Cell B as twice the value of Cell A. I have not figured out a way to do this in NetLogo.
- "However, NetLogo allows the user to deliver instructions to one specific agent, whereas Excel doesn't. In other words, Excel can only be used for systems dynamics models; NetLogo can only be used for agent-based models.
- "NOVA, meanwhile, acts as a fusion of these. Agents and connections can and indeed must be defined mathematically, but each agent can be addressed individually. NOVA is more flexible than Excel and NetLogo in that it can be used for either agent-based or systems-dynamics models. Its graphical construction, based on stocks and flows, is perhaps more intuitive and user-friendly than NetLogo's programming screen or Excel's spreadsheet. It is also easier to input formulas in NOVA than in NetLogo, though its format for doing so is less intuitive than Excel's."
By this point, either you are fairly clear on what's going on, or you have given up on this gibberish. In either case, dear reader, I think you're bored, so let's move on.
The effect of networks on people's knowledge is something advertisers and political analysts examine and use regularly. Social scientists like it, too, for nerdier reasons. I fall squarely in that camp. However, understanding network effects is useful. If you can understand how new habits spread in a population, you can try to change that population. I think this has already been done in attempts to counter juvenile delinquency. Some people have more connections or more influence (read Malcolm Gladwell's The Tipping Point for more on this). You can alter the habits of any kid, but if you figure out the more influential people in the social network and alter their habits, you can also affect a sizeable part of the network.
This is also why models are so useful for social science. A while ago, my advisor told me that statistics, simulations, and modeling allow us to determine what kinds of interventions are likely to be the most useful without having to carry out hundreds of sample interventions. I think this is why she suggested I take this course for Winter Term.
I modeled a social network, a group of people who are all linked to each other, directly or indirectly. The "links" are social connections--knowing someone well enough to pass on news or gossip to them. This is a model of a face-to-face social network in which information is spread by two people talking to each other, not, say, Facebook or the State of the Union address or a message on a whiteboard. Those can be passively absorbed by people other than the explicitly intended recipient, which would be a lot harder to model.
I wanted to explore how information diffuses through such a network under different conditions, so I made nearly all the parameters involved in its creation malleable--the user can change them easily by moving a slider bar on the user-interface screen.
They can change the size of the network (anywhere from ten to three hundred people), the number of people who know the information at the outset, the average number of people each person is linked to, the number of people each person who knows will try to tell, how likely a person is to spread the information themselves once they receive it, and how likely a person is to tell a friend of a friend (someone they are not directly linked to).
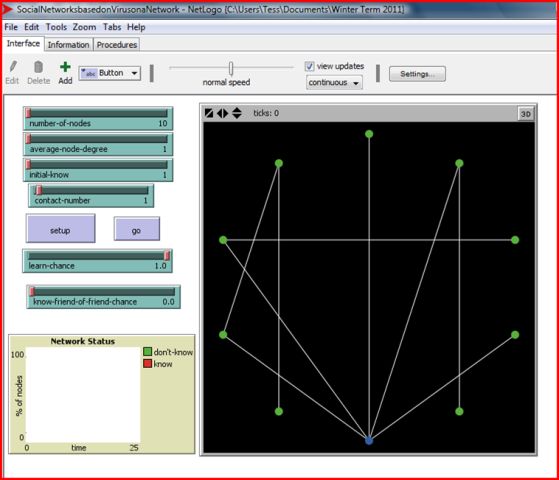
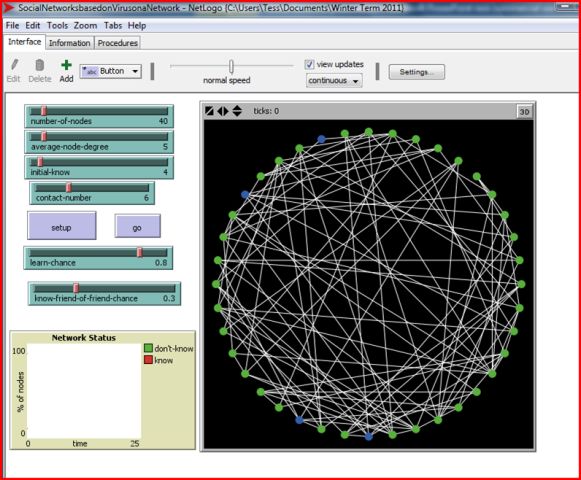
I examined the effects of each of these variables individually. The likelihood of someone "remembering" the information after having been told it had the single largest effect on how fast and how far the information spread in my experiments. Due to a color-coding scheme I'd worked out, I could see which people had just learned the information after each "tick" (time unit/turn of telling people), which ones had no one left who didn't know to tell, and which ones had passed on their information in a past tick and were now inactive. That way, I could see when the information saturated the entire network or when it died out because all those who "knew" had no connections who didn't know to tell. If people didn't accept the information, they didn't pass it along, and it died out very quickly.
Being able to communicate with friends of friends was the next-most effective. Behold, a section of a network:
A-----B-----C----D
|
|
W
Let's say C had the information and passed it on to B. B is linked to A and C. C already knows the information, obviously, and so does A, because W told her. D doesn't know yet. So B can't tell A or C--they already know. Normally, the information would die out with B. But if we create a chance that B can tell people who know people B knows--in this case, W and D--then there's a chance that B will tell D and the information will continue spreading. It stops the info from dead-ending.
The next-most important was the link density in the network--the average number of people each person was connected to. If each person only knows one or two other people, they're more likely to run into situations like the one above, where all the people they're connected to already know. But if each person knows a lot of people, that's less likely to happen, and the information keeps spreading.
Interestingly, the number of people each person tries to tell and the number of people who know at the outset do not have much of an effect on their own. Only when they are combined with high interconnectedness (links to many people) or with the ability to contact friends of friends do these have much effect. In those cases, though, the effect is remarkable.
Whew, this is hard to describe without the model for you to play with. I hope it's made sense and been interesting!
Similar Blog Entries
An Ode to Studying Abroad
December 5, 2024
I knew one of my main goals coming to Oberlin would be studying abroad. Little did I imagine that my dream would come true five months into my freshman year!

Mi Viaje Maravilloso en Guadalajara - Part 2
September 29, 2024
The academics and weekly schedule from my Winter Term trip to Guadalajara, Mexico.

